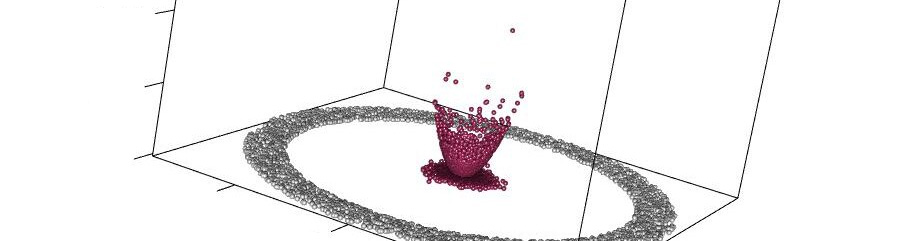
With Government bodies, policy makers, and institutions being entrusted with directing increasingly large shares of the collective public effort (as measured by GDP) there is an enormous public interest in ensuring that the right policies are implemented at the right time, and for an appropriate duration. This has led to...
- January 4, 2023